谷歌的TensorFlow是训练和部署深度学习模型的领先工具之一. 它能够优化具有数亿个参数的极其复杂的神经网络架构, 它还附带了一系列硬件加速工具, 分布式训练, 生产工作流程. 这些强大的功能可能会使它在深度学习领域之外显得令人生畏和不必要.
但 TensorFlow 对于不直接相关的简单问题,是否可以访问和使用 训练深度学习模型. TensorFlow的核心是一个优化的张量操作库(向量、矩阵等).)和用于对任意计算序列执行梯度下降的微积分运算. 经验丰富的数据科学家将认识到“梯度下降”是计算数学的基本工具, 但它通常需要实现特定于应用程序的代码和方程. 正如我们将看到的,这就是TensorFlow现代“自动分化”架构的用武之地.
在进入TensorFlow代码之前, 熟悉梯度下降和线性回归是很重要的.
用最简单的话来说, 它是一种数值技术,用来找到一个方程系统的输入,使其输出最小. 在…的背景下 机器学习这个方程组就是我们的 模型,输入是未知的 参数 模型的,输出是a 损失函数 为了最小化,它表示模型和我们的数据之间有多少误差. 对于某些问题(如线性回归), 有一些方程可以直接计算使误差最小化的参数, 但对于大多数实际应用来说, 我们需要像梯度下降这样的数值技术来得到一个满意的解.
本文最重要的一点是,梯度下降法通常需要设置我们的方程,并使用微积分推导损失函数和参数之间的关系. 使用TensorFlow(和任何现代自动分化工具), 微积分已经算出来了, 所以我们可以专注于设计解决方案, 而且不用花时间在执行上.
这是一个简单的线性回归问题. 我们有150名成年男性的身高(h)和体重(w)的样本, 我们先来猜测一下这条直线的斜率和标准差. 在大约15次梯度下降迭代之后,我们得到了一个接近最优的解.

让我们看看如何使用TensorFlow 2生成上述解决方案.0.
对于线性回归,我们说权重可以通过高度的线性方程来预测.
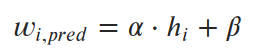
我们想要找到参数α和β(斜率和截距),使预测值和真实值之间的平均平方误差(损失)最小化. 所以我们的 损失函数 (在这种情况下,“均方误差”或MSE)是这样的:
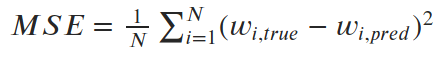
我们可以看到一些不完美直线的均方误差是怎样的, 然后是精确解(α=6.04, β=-230.5).
让我们用TensorFlow来实现这个想法. 首先要做的是用张量编码损失函数 tf.* 功能.
Def calc_mean_sq_error(高度,权重,斜率,截距):
Predicted_wgts =斜率*高度+截距
Errors = predicted_wgts -权重
Mse = tf.reduce_mean(错误* * 2)
返回mse
这看起来很简单. 所有的标准代数算子对于张量都是重载的, 所以我们只需要确保我们要优化的变量是张量, 我们使用 tf.* 其他任何东西的方法.
然后,我们要做的就是把它放入梯度下降循环中:
Def run_gradient_descent(高度,权重,init_slope, init_icept, learning_rate):
任何作为梯度计算一部分的值都需要是变量/张量
Tf_slope = tf.变量(init_slope dtype =“float32”)
Tf_icept = tf.变量(init_icept dtype =“float32”)
#硬编码25次梯度下降迭代
对于范围(25)内的I:
#在跟踪所有梯度的“GradientTape”下进行所有计算
与特遣部队.GradientTape ()作为磁带:
磁带.看((tf_slope tf_icept))
这是和之前一样的均方误差计算
预测= tf_slope * height + tf_icept
误差=预测-权重
损耗= tf.reduce_mean(错误* * 2)
#自动调差魔法! 损失计算和参数之间的梯度
Dloss_dparams =磁带.梯度(loss, [tf_slope, tf_icept])
#梯度指向+损失,所以减去“下降”
Tf_slope = Tf_slope - learning_rate * dloss_dparams[0]
Tf_icept = Tf_icept - learning_rate * dloss_dparams[1]
让我们花点时间欣赏一下这是多么整洁. 梯度下降法需要计算损失函数对我们要优化的所有变量的导数. 应该会涉及到微积分,但实际上我们什么都没做. 神奇之处在于:
tf.GradientTape ().从不同的起点看这个过程是怎样的?

梯度下降非常接近最优MSE, 但实际上收敛到的斜率和截距都与两个例子中的最优值大不相同. 在某些情况下, 这就是收敛到局部最小值的梯度下降, 梯度下降算法的内在挑战是什么. 但是线性回归可以证明只有一个全局最小值. 那么我们是怎么得到错误的斜率和截距的呢?
在这种情况下,问题在于我们为了演示而过度简化了代码. 我们没有对数据进行标准化, 斜率参数与截距参数具有不同的特征. 坡度的微小变化会导致损失的巨大变化, 而截距的微小变化影响很小. 可训练参数在尺度上的巨大差异导致斜率在梯度计算中占主导地位, 截距参数几乎被忽略.
因此,梯度下降法可以有效地找到非常接近初始截距猜测的最佳斜率. 由于误差如此接近最优值, 它周围的梯度很小, 所以每次迭代只移动一点点. 首先对我们的数据进行规范化可以极大地改善这种现象, 但它不会消除它.
这是一个相对简单的例子, 但是我们将在下一节中看到,这种“自动区分”功能可以处理一些相当复杂的东西.
下一个例子是基于我去年参加的深度学习课程中的一个有趣的深度学习练习.
问题的要点是,我们有一个“变分自动编码器”(VAE),它可以从一组32个正态分布的数字中产生逼真的面孔. 识别嫌疑人, 我们希望使用VAE来生成一组不同的(理论上的)面孔供证人选择, 然后通过生成更多与所选面孔相似的面孔来缩小搜索范围. 对于这个练习, 建议将初始向量集随机化, 但我想找到一个最优初始状态.
我们可以这样表述这个问题:给定一个32维空间, 找到一组X个单位向量它们最大程度地分散开来. 在二维空间中,这很容易精确计算. 但是对于三维(或32维)!),没有直截了当的答案. 然而, 如果我们能定义一个合适的损失函数当我们达到目标状态时,它是最小的, 也许梯度下降法可以帮助我们到达那里.
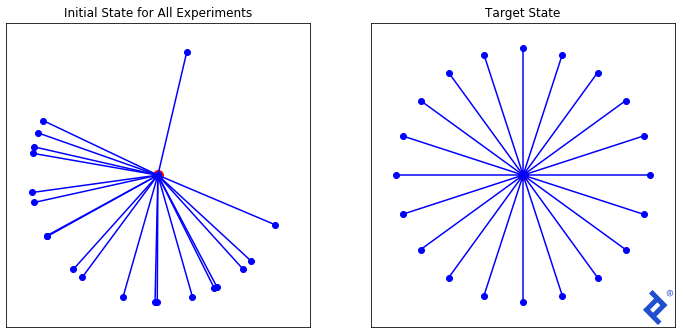
我们将从如上所示的20个随机向量集开始,并使用三种不同的损失函数进行实验, 每一个都越来越复杂, 来演示TensorFlow的功能.
让我们首先定义我们的训练循环. 我们将把所有的TensorFlow逻辑放在 自我.calc_loss () 方法,然后我们可以简单地为每个技术重写该方法,循环这个循环.
定义尝试不同损失函数的框架
基类实现循环,子类重载自我.calc_loss ()
类VectorSpreadAlgorithm:
# ...
Def calc_loss(自我, tensor2d):
引发NotImplementedError("在派生类中定义这个")
Def one_iter(自我, i, learning_rate):
#自我.vecs是一个20x2张量,表示20个2D向量
Tfvecs = tf.convert_to_tensor(自我.vec dtype =特遣部队.float32)
与特遣部队.GradientTape ()作为磁带:
磁带.观察(tfvecs)
损失=自我.calc_loss (tfvecs)
#魔法又来了. 对的导数
#输入向量
梯度=磁带.tfvecs梯度(损失)
自我.Vecs = 自我.Vecs - learning_rate *梯度
要尝试的第一个技巧是最简单的. 我们定义了一个距离度量,它是距离最近的向量的角度. 我们想要最大化传播,但传统上把它变成最小化问题. 所以我们只取传播度规的负值
class VectorSpread_Maximize_Min_Angle(VectorSpreadAlgorithm):
Def calc_loss(自我, tensor2d):
Angle_pairs = tf.Acos (tensor2d @ tf.置(tensor2d))
Disable_diag = tf.眼睛(tensor2d.numpy ().[0]) * 2 * np.pi
Spread_metric = tf.Reduce_min (angle_pairs + disable_diag)
惯例是返回要最小化的数量,但是我们想
#最大化传播. 所以返回负价差
返回-spread_metric
一些Matplotlib魔术将产生可视化.
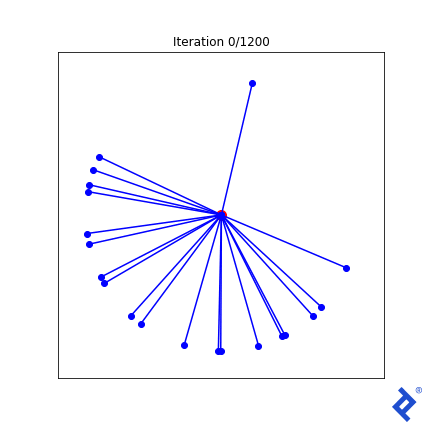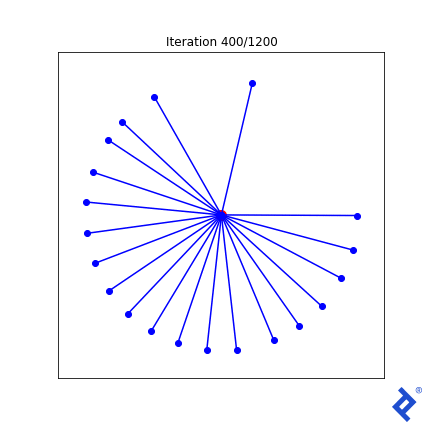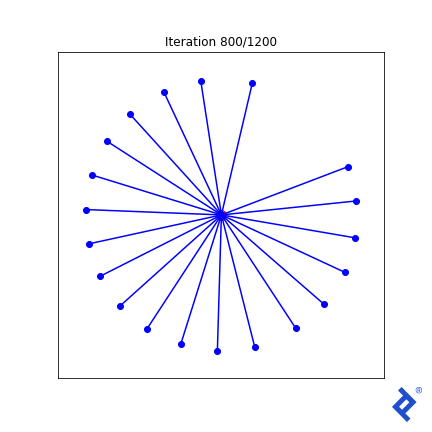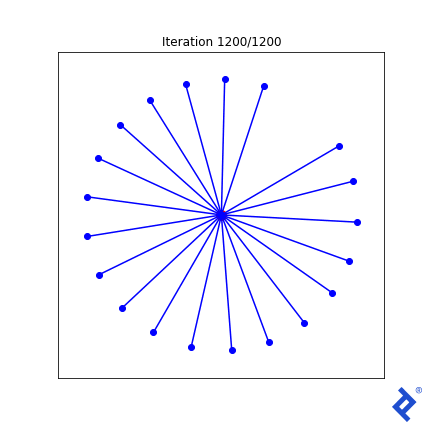
这很笨拙(毫不夸张)!),但确实有效. 一次只更新20个向量中的两个, 扩大他们之间的距离,直到他们不再是最亲密的, 然后切换到增加两个最近向量之间的夹角. 重要的是要注意 它的工作原理. 我们看到TensorFlow能够通过梯度 tf.reduce_min () 方法和 tf.这些“可信赖医疗组织”() 做正确事情的方法.
让我们尝试一些更复杂的东西. 我们知道在最优解处, 所有向量与其最近的邻向量的夹角应该相同. 我们把最小角度方差加到损失函数中.
类VectorSpread_MaxMinAngle_w_Variance (VectorSpreadAlgorithm):
Def spread_metric(自我, tensor2d):
"""假设所有行都已标准化"""
Angle_pairs = tf.Acos (tensor2d @ tf.置(tensor2d))
Disable_diag = tf.眼睛(tensor2d.numpy ().[0]) * 2 * np.pi
All_mins = tf.Reduce_min (angle_pairs + disable_diag, axis=1)
#与之前计算相同,求最小最小角
Min_min = tf.reduce_min (all_mins)
#但是现在还要计算最小角度向量的方差
Avg_min = tf.reduce_mean (all_mins)
Var_min = tf.reduce_sum(特遣部队.Square (all_mins - avg_min))
我们的价差度量现在包括一个最小化方差的术语
Spread_metric = min_min - 0.4 * var_min
和之前一样,我们想要负传播来保持最小化问题
返回-spread_metric
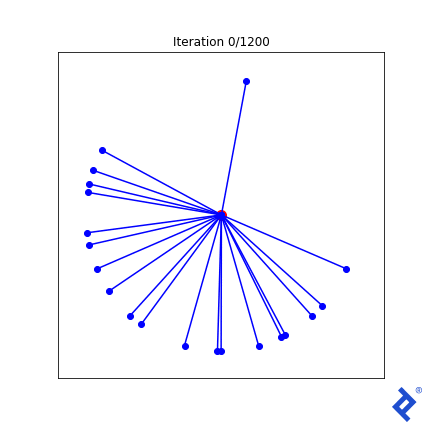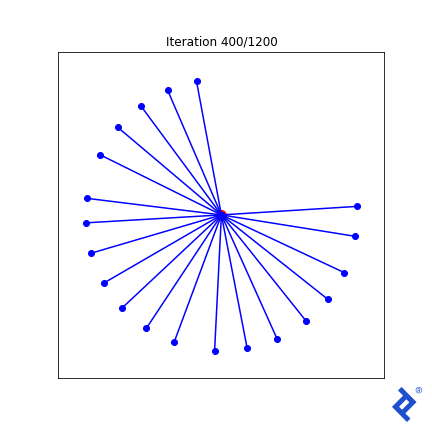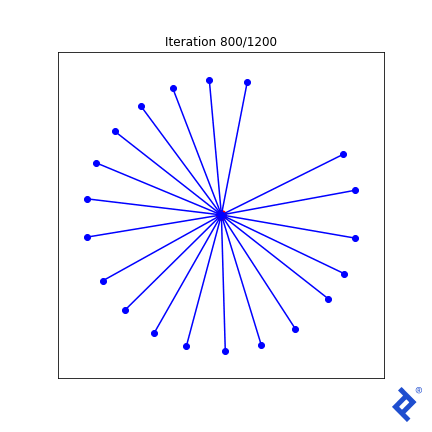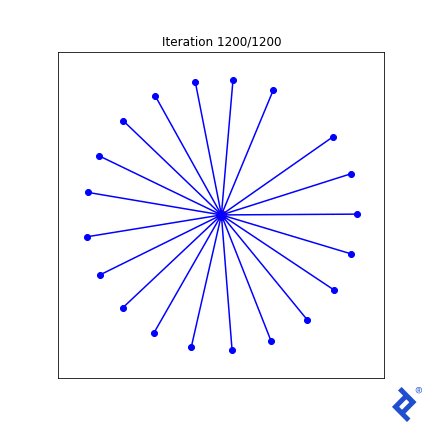
唯一的北向矢量现在迅速加入了其他矢量的行列, 因为与它最近的邻居的夹角很大,使得方差项尖峰,而方差项现在被最小化了. 但它最终仍然是由全球最小角度驱动的,这个角度仍然缓慢上升. 我需要改进的想法通常适用于二维情况,但不适用于更高的维度.
但过于关注这种数学尝试的质量是没有抓住重点的. 看看有多少张量运算涉及到均值和方差的计算, 以及TensorFlow如何成功地跟踪和区分输入矩阵中每个组件的每个计算. 我们不需要做任何手工微积分. 我们只是把一些简单的数学运算放在一起,TensorFlow为我们做了微积分.
最后,让我们再尝试一件事:基于力的解决方案. 想象一下,每个向量都是一个系在中心点上的小行星. 每颗行星都释放出一种力,使它与其他行星相互排斥. 如果我们要运行这个模型的物理模拟,我们应该最终得到我们想要的解决方案.
我的假设是梯度下降法也应该有效. 在最优解处, 每个行星与其他行星之间的切向力应该抵消为净零力(如果不是零的话, 行星会移动). 我们来计算作用在每个向量上的力的大小然后用梯度下降把它推向零.
首先,我们需要定义计算力的方法 tf.* 方法:
类VectorSpread_Force (VectorSpreadAlgorithm):
Def 为ce_a_onto_b(自我, vec_a, vec_b):
#计算力,假设vec_b被限制在单位球上
Diff = vec_b - vec_a
Norm = tf.√特遣部队.reduce_sum (diff * * 2))
Unit_为ce_dir = diff / norm
Force_magnitude = 1 / norm**
Force_vec = unit_为ce_dir * 为ce_magnitude
#投射力到这个vec上,计算多少是径向的
B_dot_f = tf.Tensordot (vec_b, 为ce_vec,坐标轴=1)
B_dot_b = tf.Tensordot (vec_b, vec_b, axes=1)
Radial_component = (b_dot_f / b_dot_b) * vec_b
减去径向分量并返回结果
返回为ce_vec - radial_component
然后,我们使用上面的力函数定义损失函数. 我们累加每个矢量上的合力并计算它的大小. 在我们的最优解中,所有的力都抵消了,力应该为零.
Def calc_loss(自我, tensor2d):
N_vec = tensor2d.numpy ().形状[0]
All_为ce_list = []
对于this_idx在范围(n_vec):
#将所有其他矢量的力累积到这个矢量上
This_为ce_list = []
对于other_idx在范围(n_vec):
如果this_idx == other_idx:
继续
This_vec = tensor2d[this_idx,:]
Other_vec = tensor2d[other_idx,:]
Tangent_为ce_vec = 自我.为ce_a_onto_b (other_vec this_vec)
this_为ce_list.追加(tangent_为ce_vec)
#使用所有n维力向量列表. 堆栈和.
Sum_tangent_为ces = tf.reduce_sum(特遣部队.堆栈(this_为ce_list))
This_为ce_mag = tf.√特遣部队.reduce_sum (sum_tangent_为ces * * 2))
#累加所有的值,在最优解处应该都是零
all_为ce_list.追加(this_为ce_mag)
#我们想要最小化总力的总和,所以简单地堆叠,求和,返回
返回特遣部队.reduce_sum(特遣部队.堆栈(all_为ce_list))

这个解决方案不仅效果很好(除了前几帧有些混乱)。, 但真正的功劳要归功于TensorFlow. 这个解决方案涉及多个 为 循环,一个 if 声明, 还有一个庞大的计算网络, TensorFlow成功地为我们追踪了所有的梯度.
说到这里,读者可能会想,“嘿! 这篇文章不是关于深度学习的!“但从技术上讲,引言指的是超越。”培训 深度学习模型.“在这种情况下,我们没有 培训, 而是利用预先训练的深度神经网络的一些数学特性来欺骗它,让它给我们错误的结果. 事实证明,这比想象的要容易得多,也有效得多. 而它所需要的只是另一小团TensorFlow 2.0代码.
我们首先找到一个要攻击的图像分类器. 我们将使用一个最常用的解 狗和. Cats Kaggle比赛; specifically, 解决方案 由卡格勒(Kaggler)提出.“这一切都归功于他们提供了一个有效的猫对狗模型,并提供了很好的文档. 这是一个强大的模型,由18个神经网络层的1300万个参数组成. (欢迎读者在相应的笔记本上阅读更多内容.)
请注意,这里的目标不是突出这个特定网络中的任何缺陷,而是说明如何做到这一点 任何具有大量输入的标准神经网络都是脆弱的.
稍微修补一下, 我能够弄清楚如何加载模型并对图像进行预处理,以便通过它进行分类.

这看起来是一个非常可靠的分类器! 所有样本分类都是正确的,置信度在95%以上. 我们来攻克它!
我们想要生成一张明显是猫的图像,但让分类器以高置信度判定它是狗. 我们怎么能做到呢?
让我们从一张它能正确分类的猫图片开始, 然后计算给定输入像素的每个颜色通道(值0-255)的微小修改如何影响最终分类器输出. 修改一个像素可能不会做太多, 但也许所有128x128x3 = 49的累积调整,152像素值将达到我们的目标.
我们怎么知道推每个像素的方式? 在正常的神经网络训练中, 我们尝试最小化目标标签和预测标签之间的损失, 在TensorFlow中使用梯度下降同时更新所有1300万个自由参数. 在这种情况下, 我们将保持1300万个参数不变, 并调整输入本身的像素值.
损失函数是什么? 好吧,这是图像看起来像一只猫的程度! 如果我们计算cat值相对于每个输入像素的导数, 我们知道用哪种方式推每一个来最小化猫的分类概率.
def adversarial_modify(受害者,to_dog=False, to_cat=False):
#我们只需要四个梯度下降步骤
对于(4)范围内的I:
tf_受害_img = tf.convert_to_tensor (victim_img dtype =“float32”)
与特遣部队.GradientTape ()作为磁带:
磁带.观察(tf_victim_img)
#通过模型运行图像
Model_output = 模型(tf_受害者)
最小化猫的自信,最大化狗的自信
Loss = (模型_output[0] - 模型_output[1])
Dloss_dimg =磁带.tf_victim_img梯度(损失)
#忽略梯度大小,只关心符号,+1/255或-1/255
Pixels_w_pos_grad = tf.cast(dloss_dimg > 0.0, “float32”) / 255.
Pixels_w_neg_grad = tf.cast(dloss_dimg < 0.0, “float32”) / 255.
受害img =受害img - pixels_w_pos_grad + pixels_w_neg_grad
Matplotlib魔术再次帮助可视化结果.

哇! 在人眼看来,这些图片都是一样的. 然而,经过四次迭代,我们已经让分类器相信这是一只狗,有99.4%置信度!
让我们确保这不是侥幸,它也适用于其他方向.

成功! 分类器最初正确地预测了这是一只98分的狗.百分之四的信心,现在相信它是一只百分之九十九的猫.8%的信心.
最后,让我们看一个样本图像补丁,看看它是如何变化的.
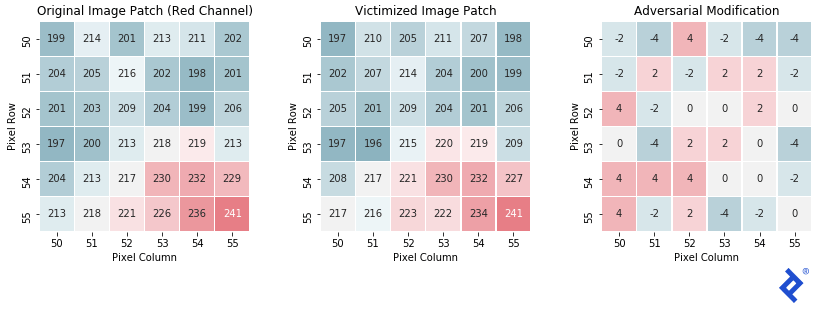
正如预期的, 最后的补丁和原来的非常相似, 每个像素只在红色通道的强度值中移动-4到+4. 这种变化不足以让人类分辨出两者的区别, 但是完全改变了分类器的输出.
在本文中, 为了简单和透明,我们已经研究了手动对可训练参数应用梯度. 然而,在现实世界中,数据科学家应该直接投入使用 优化器,因为它们往往更有效,而不会增加任何代码膨胀.
有许多流行的优化器, 包括RMSprop, Adagrad, 和Adadelta, 但最常见的是“可能” 亚当. 有时, 它们被称为“自适应学习率方法”,因为它们对每个参数动态地保持不同的学习率. 其中很多都使用动量项和近似高阶导数, 目标是避免局部最小值,实现更快的收敛.
在塞巴斯蒂安·鲁德的动画里, 我们可以看到各种优化器沿着损失面下降的路径. 我们所演示的手工技术与“SGD”最为相似.” The best-per为ming 优化器 won’t be the same one 为 every loss surface; however, 更高级的优化器 do 通常比简单的表现更好.

然而,成为优化器方面的专家很少有用——即使对于那些热衷于提供优化器的人也是如此 人工智能开发服务. 这是一个更好地利用开发人员的时间来熟悉一些, 只是为了了解它们是如何改善TensorFlow中的梯度下降的. 之后,他们就可以使用了 亚当 默认情况下,只有当他们的模型不收敛时才尝试不同的模型.
对于真正对这些优化器如何以及为什么工作感兴趣的读者, 罗德的概述是关于该主题的最好和最详尽的资源之一.
让我们更新第一节中的线性回归解决方案,以使用优化器. 以下是使用手动梯度的原始梯度下降代码.
#手动梯度下降操作
Def run_gradient_descent(高度,权重,init_slope, init_icept, learning_rate):
Tf_slope = tf.变量(init_slope dtype =“float32”)
Tf_icept = tf.变量(init_icept dtype =“float32”)
对于范围(25)内的I:
与特遣部队.GradientTape ()作为磁带:
磁带.看((tf_slope tf_icept))
预测= tf_slope * height + tf_icept
误差=预测-权重
损耗= tf.reduce_mean(错误* * 2)
梯度=磁带.梯度(loss, [tf_slope, tf_icept])
Tf_slope = Tf_slope - learning_rate * gradients[0]
Tf_icept = Tf_icept - learning_rate * gradients[1]
现在,这里是使用优化器的相同代码. 你会看到它几乎没有任何额外的代码(更改的行以蓝色突出显示):
#梯度下降与优化器(RMSprop)
def run_gradient_descent(高度,权重,init_slope, init_icept, learning_rate):
Tf_slope = tf.变量(init_slope dtype =“float32”)
Tf_icept = tf.变量(init_icept dtype =“float32”)
#组可训练参数到一个列表
Trainable_params = [tf_slope, tf_icept]
在训练循环之外定义你的优化器(RMSprop)
优化器= keras.优化器.RMSprop (learning_rate)
为 i in 范围(25):
# GradientTape循环也是一样的
与 tf.GradientTape () as 磁带:
磁带.看(trainable_params)
预测= tf_slope * height + tf_icept
误差=预测-权重
损耗= tf.* * reduce_mean(错误2)
我们可以直接在梯度计算中使用可训练参数列表
梯度=磁带.梯度(损失, trainable_params)
#优化器总是以最小化损失函数为目标
优化器.apply_gradients (zip(梯度,trainable_params))就是这样! 我们定义了 RMSprop 优化器之外的梯度下降循环,然后我们使用 优化器.apply_gradients () 方法在每次梯度计算后更新可训练参数. 优化器是在循环之外定义的,因为它将跟踪历史梯度,以便计算动量和高阶导数等额外项.
我们来看看 RMSprop 优化器.

看起来不错! 现在我们来试试 亚当 优化器.

哇,这里发生了什么? 看来亚当体内的动量机制导致它超越了最优解并多次逆转. 正常情况下, 这种动量机制有助于处理复杂的损失面, 但在这个简单的例子中,它伤害了我们. 这强调了在训练模型时将优化器的选择作为调优超参数之一的建议.
任何想要探索深度学习的人都希望熟悉这个模式, 因为它在自定义TensorFlow架构中被广泛使用, 哪里需要有复杂的损失机制,而这些机制不容易在标准工作流程中进行包装. 在这个简单的TensorFlow梯度下降示例中, 只有两个可训练的参数, 但在处理包含数亿个参数的体系结构时,这是必要的.
所有的代码片段和图像都是从笔记本中生成的 相应的GitHub repo. 它还包含所有部分的摘要, 与链接到个别笔记本, 对于想要查看完整代码的读者. 为了简化信息, 我们遗漏了很多细节,这些细节可以在广泛的内联文档中找到.
我希望这篇文章是有洞察力的,它能让你思考在TensorFlow中使用梯度下降的方法. 即使你自己不使用它, 希望它能让你更清楚地了解所有现代神经网络架构是如何工作的——创建一个模型, 定义一个损失函数, 并使用梯度下降来拟合模型到您的数据集.

作为谷歌云合作伙伴,Toptal的谷歌认证专家可以为公司服务 对需求 为了他们最重要的项目.
TensorFlow通常用于训练和部署各种应用程序的AI代理, 例如计算机视觉和自然语言处理(NLP). 在引擎盖下, 它是一个用于优化大量计算图的强大库, 深度神经网络是如何定义和训练的.
Tensorflow是谷歌为尖端人工智能研究和大规模部署人工智能应用而创建的深度学习框架. 在引擎盖下, 它是一个优化的库,用于进行张量计算并通过它们跟踪梯度,以应用梯度下降算法.
梯度下降是一种基于微积分的数值技术,用于优化机器学习模型. 给定模型的误差被定义为模型参数的函数, 然后应用梯度下降法来调整这些参数以使误差最小化.
梯度下降的工作原理是将模型的误差表示为其参数的函数. 利用微积分, 我们可以计算这个误差如何随着每个参数的调整而变化——它的梯度——然后迭代地调整这些参数,直到模型的误差最小化.
梯度下降法是一种求函数近似最小值的数值方法. 它通常与训练人工神经网络有关,其目标是最小化误差或损失函数.
Alan的机器学习专业知识涵盖导弹防御系统的视觉目标识别模型, 实时NLP, 以及财务评估工具.
 作者都是各自领域经过审查的专家,并撰写他们有经验的主题. 我们所有的内容都经过同行评审,并由同一领域的Toptal专家验证.
作者都是各自领域经过审查的专家,并撰写他们有经验的主题. 我们所有的内容都经过同行评审,并由同一领域的Toptal专家验证.

